Azon ismerőseink, akik ékezet nélkül írnak sms-t, nem feltétlenül hanyagok vagy igénytelenek. Lehet, hogy csak spórolnak.
Hogyan kerültek a számítógépre az ékezetek? Az informatika mindig is komoly gondokkal küzdött, amikor az angol ábécében nem szereplő jelek megjelenítéséről volt szó; a helyzet mostanára sokat javult, de még mindig nem minden téren tökéletes a nemzetközi támogatás. Miért alakult ez így, és hogyan fejlődött a karakterkódolás a kezdetektől napjainkig? Sok furcsaságot tartalmazó történeti áttekintésünk a zászlólengetéstől a Unicode SMS-ekig.
Kezdetben vala a morze
Ahhoz, hogy egy modern informatikai rendszer képes legyen tárolni a szöveget, először szükség van egy úgynevezett karakterkódolási szisztémára, ami az írásjeleket számokká alakítja, mert a számítógép csak egyesekkel és nullákkal tud mit kezdeni. De az első karakterkódolási módszerek még nem számokat rendeltek a betűkhöz, hanem egészen más dolgokat. Ezek közül több a maga speciális területén a mai napig fennmaradt: a morzeábécé hosszú és rövid jeleket használ, a tengerészetben pedig színes jelzőlobogókkal lehet a hajózásban fontos információk mellett magukat a latin betűket is jelölni. Ha két tengerész látótávolságban van, akkor pedig a zászlószemaforral is kommunikálhatnak:
</h3> ">Igazán merész olvasóink a japán szótagírásos zászlójeleket is kipróbálhatják!
Az első olyan rendszer, ami a maiakhoz hasonlóan kettes számrendszerbeli számokkal adta meg a betűket, az 1874-ben Franciaországban feltalált Baudot-kód volt: ez öt számjeggyel – öt biten – tárolta a latin ábécét és egyéb írásjeleket, tehát 25 = 32 féle jelet lehetett vele megkülönböztetni. Ez még úgy sem túl sok, hogy lehetőség nyílt betűk és számok-írásjelek közötti váltásra, tehát kétszer ennyi karakterrel lehetett dolgozni. A hiányzó betűk problémája már itt megjelent, tehát tulajdonképpen egyidős a modern karakterkódolással magával; a Baudot-kód ugyanis nem volt képes a francia ékezetek és mellékjelek helyes kezelésére. Csakúgy, amint a magyarra sem, ennek ellenére mégis ennek a rendszernek módosított változatát használták a magyar telexhálózat távírógépei is, a régi táviratokból ismerős módon átvive az ékezeteket: például ö helyett oe, ő helyett oeoe szerepelt. (Egészen 2002-ig üzemelt Magyarországon nyilvános telexhálózat, habár a rendszerváltás után inkább csak vegetált: fénykorát évtizedekkel korábban élte, főleg állami szervek, nagyvállalatok használták.)
Feltűnik a színen a kalapos ű
A Baudot-kódra épülő rendszereket az ASCII váltotta fel, ez már a számítástechnikából is ismerős lehet. Az ASCII egy amerikai szabvány, a neve is erre utal: American Standard Code for Information Interchange = Amerikai Szabványos Információcserélési Kód. 1963-ban adták ki első változatát, akkor még szintén a különböző távírógépekre tervezve. Hét biten tárolta a karaktereket, tehát itt már 27 = 128 lehetőség adódott, viszont nem lehetett duplázni – ez teljesen szándékos volt a készítők részéről, mert így egy átvitt jelsorozat értéke nem függött semmi mástól, a változtatás sokkal egyszerűbb műszaki megoldásokat tett lehetővé.
Az eredeti ASCII szabvány számos üres helyet tartalmazott, ide 1967-ben bekerültek a kisbetűk, hogy ne csak nagybetűket lehessen átvinni. Ugyanekkor vezették be azt az eljárást is, miszerint nem egyben tárolják az ékezetes betűket, hanem egy ékezet mindig a betűje után szerepel és külön jelnek számít. Viszont csak hatféle ékezet szerepelt a készletben, és ezek is különböző más írásjelekkel osztoztak a funkción: például az aposztróf egyben a magyar á, é stb. betűkének megfelelő ékezetnek számított.
Az ASCII és a kisebb-nagyobb átalakításaival született szabványok rohamosan elterjedtek az egész világon, annak ellenére, hogy meglehetősen korlátozottak voltak a lehetőségeik. A számítástechnika fejlődésével megjelentek a 8 bitre kiterjesztett kódlapok, amelyekbe a 128 bevált ASCII karakter mellé 128 új is befért... volna, ha nem lett volna szükség a grafikus felületek kialakulásával különböző vonalakra, sarkokra és egyéb elemekre, amiket először szintén ide pakoltak be. Az egyik legjobban elterjedt ilyen próbálkozás az IBM fejlesztette 437-es kódlapvolt:
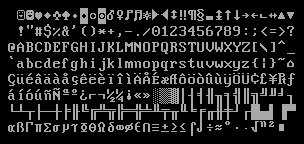
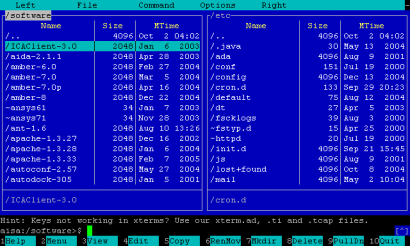
Azt is láthatjuk, hogy azért sikerült több ékezetes karaktert belegyömöszölni a táblázatba, viszont sok minden kimaradt, például az őés ű is. (Innen ered a hullámos õ és a kalapos û, mint szükségmegoldás.)Nem csoda, hiszen ezeket Magyarországon kívül csak egy-két kis helyen használják, például az ő-t a Feröer-szigeteken:

Magyarországon éppen ezért a 437-es helyett a 852-es „közép-európai” kódlapot használták, ebben már benne volt minden magyar ékezetes betű, viszont cserébe hiányzott több sarokelem – aki használt a DOS-korszakban számítógépet, valószínűleg még emlékszik arra, hogy ez kissé elrondította a grafikus felületeket. Csehországban született erre házimegoldás, a Kamenický kódolás, ebből viszont a nyugat-európai karakterek maradtak ki.
Unicode, a megváltás?
A hasonló toldozás-foldozás mellett nehézséget okozott a kódtáblázatok közötti választás is. Jobb esetben tudta a felhasználó – és az általa használt szoftver –, hogy melyik szöveghez melyik kódlapot használja, de nem mindig! Japánban még külön szó is született arra a jelenségre, amikor rossz kódolással jelenik meg valami: ez a mojibake (magyar fonetikával modzsibake).
Erre a problémára válaszul született a Unicode (ejtsd: junikód). Tervezői azt tűzték ki célul, hogy minden írás minden karaktere belekerüljön! Itt még nem tartunk, de egyre bővül a választék. Szépen hangzik, de a dolog nem egyszerű: ha minden jelnek van egy száma, akkor nagyon-nagyon hosszú számokra van szükség ahhoz, hogy akár egy egész rövid szöveget is leírjunk. Persze a gyakorlatban nagyon sok jelre nincs szükség, például a föníciai ábécét valószínűleg kevesen használják a mindennapi életben (itt ki lehet próbálni, tudja-e a böngészőnk). Hogyan lehet ezt a dilemmát feloldani?
A trükkös megoldás az, hogy kétszer végezzük el a hozzárendelést. Először az írásjeleket rendeljük a maguk egyedi Unicode azonosítószámához, majd az azonosítószámot valamelyik UTF ( = Unicode Transzformációs Formátum) kódlaphoz. Vannak rövidebb és hosszabb UTF kódlapok, a legelterjedtebb az ASCII-hoz hasonlóan 8 bites számokat használ (ez az UTF-8), de létezik UTF-32 is, amiben minden jelenlegi Unicode karakter benne van egyszerre (32 biten 232 = 4 294 967 296 különböző jel fér el!), viszont cserébe négyszer annyi helyet foglal a vele rögzített szöveg.
Általában nem gond a nagy kódtábla – kivéve, ha nagyon kevés hely áll rendelkezésünkre. Mikor találkozunk ezzel a mindennapi életben? Leginkább akkor, ha SMS-t szeretnénk küldeni mobiltelefonunkról. A telefonokban általánosan használt GSM kódlap nem tartalmaz minden magyar ékezetet, viszont ma már a modernebb készülékeken lehet a Unicode-ot is használni. Igen ám, csak ez több helyet foglal, így az elküldhető üzenet is rövidebb lesz, vagy – szolgáltatótól függően – két részben küldődik. Lehet, hogy a telefon szoftvere a két részre vágást és újra összeillesztést magától elvégzi, nekünk pedig fel sem tűnik, hogy duplán vagy akár triplán fizettünk az SMS-ért. Ha ez gondot okoz, érdemes a beállításokban megkeresni a kódolást és a Unicode helyett valamelyik másik lehetőséget kiválasztani! Sajnos egyre inkább jelennek meg olyan készülékek, amelyeknek vagy a Unicode az alapbeállítása, vagy nem is lehet másra átállítani őket – ilyen esetben talán elvárható lenne a szolgáltatótól, hogy a technológiaváltás miatti árkülönbséget ne hárítsa teljesen a fogyasztóra, de erre egyelőre várhatunk...
Takács Boglárka